SPDK简介—软硬件原理
spdk软硬件原理

SPDK主要提供了用户态存储的功能,绕过了kernel,实现了高性能以及可扩展的特性。
除了针对NVMe SSD的SPDK,还有针对网卡的DPDK、针对RDMA的InfiniBand Verbs、异构场景下DPU,它们都具备了kernel甚至CPU by pass的能力。
可以发现这些硬件都是PCIe设备,遵循了PCIe规范,利用PCIe的特性,使得对应驱动可以迁移至用户态。理解了PCIe软硬件交互逻辑,就能很好得理解这一系列by pass原理。
PCIe概述
传统的基于PCI总线的拓扑图如下所示,外设共享了一条PCI总线,当需要传输数据时,需要向仲裁器发出申请,获得权限后再独占PCI总线使用。
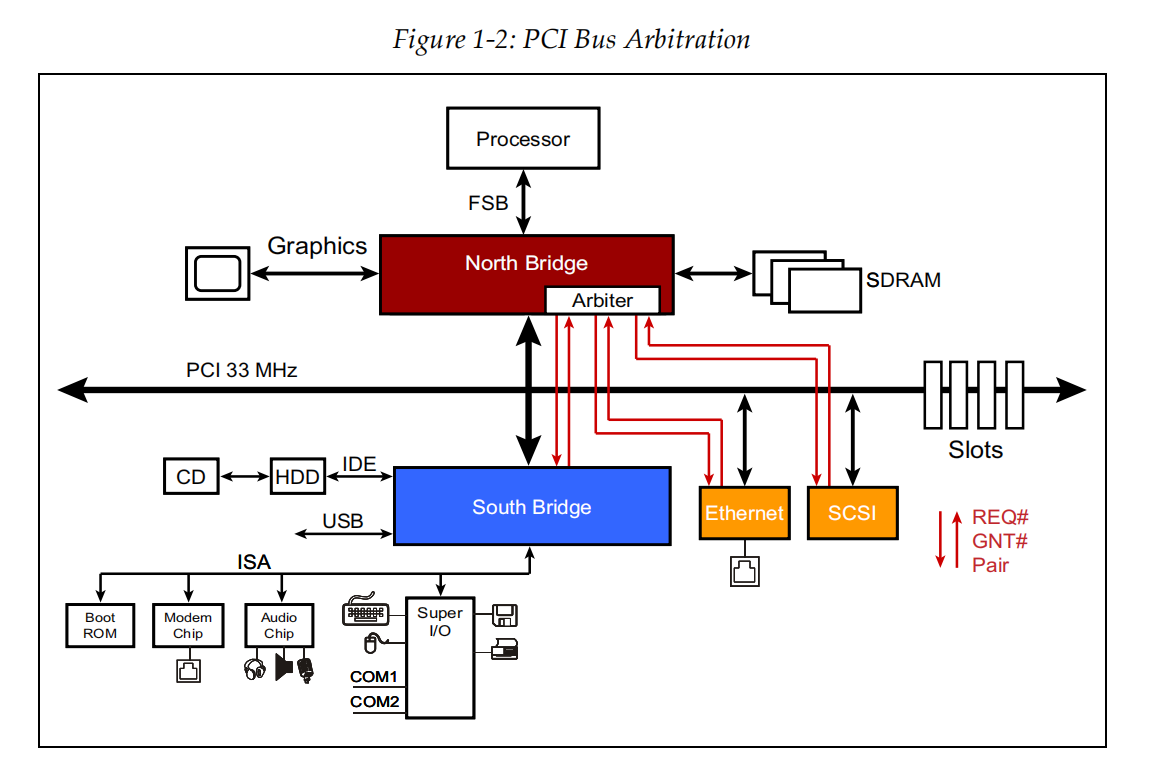
到了PCIe时代,PCIe-device间传输是全双工通信(Spec称之为双向单工通信),设备之间连接可以有1, 2, 4, 8, 12, 16, or 32 Lanes,多条Lanes可以提升带宽能力。
如图所示,Root Complex和EP(endpoint)之间,EP和EP之间都变成了点对点传输,极大地提升了带宽。
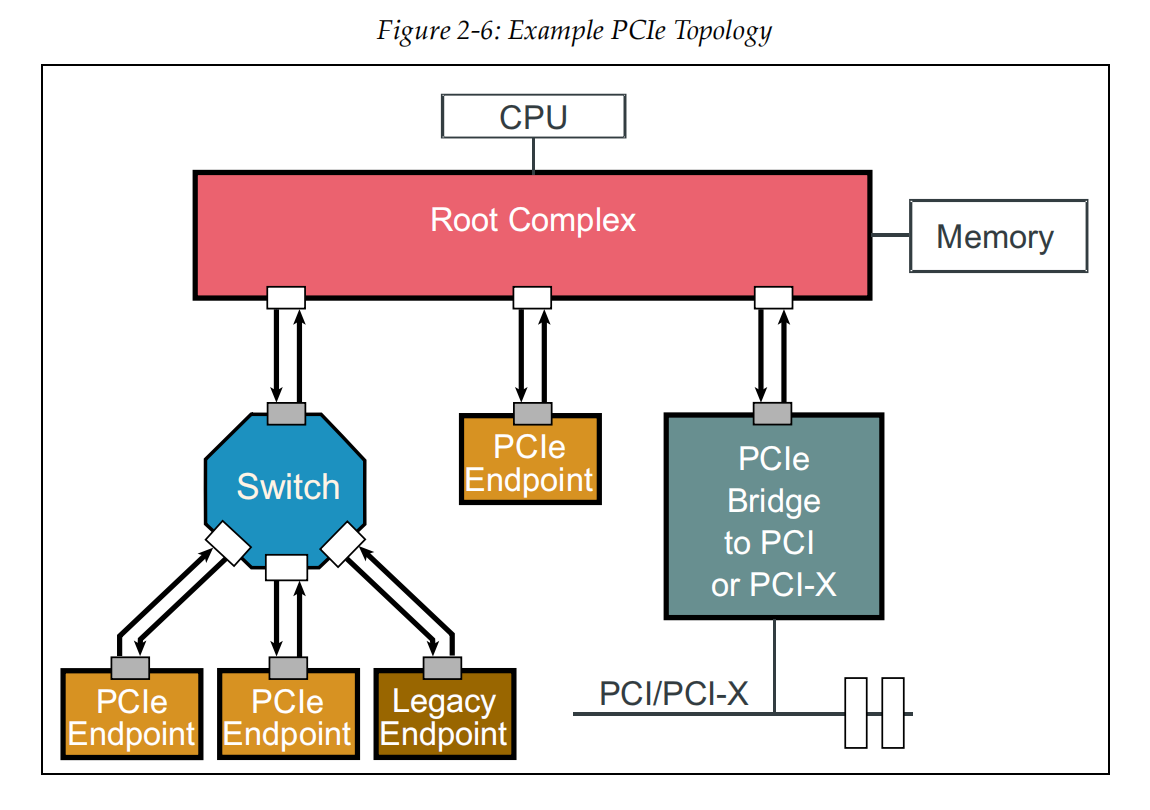
PCIe有几个比较重要的概念,理解了这些概念之后,就会明白软硬件交互的基本逻辑,一张图来展示这些概念:
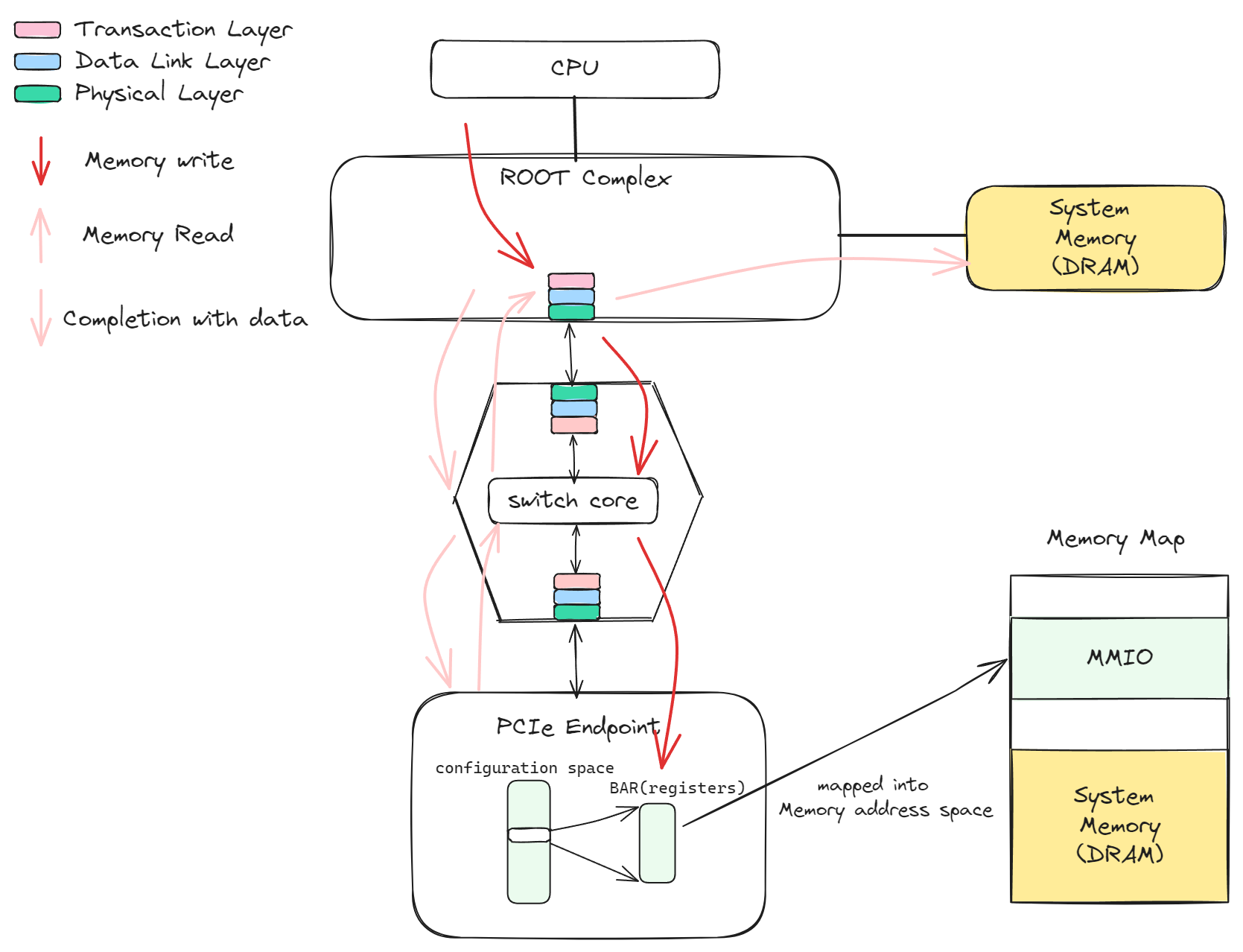
传输模型:PCIe的传输分为三层,事务层、数据链路层和物理层,类似于网络传输模型,数据从Root Complex到Endpoint的过程中存在多次的装包和解包。
Root Complex:RC用来生产事务层请求(TLP),当CPU访问的内存地址属于MMIO时,就会生成对应的TLP传输到对应的PCIe设备中去。
MMIO:Memory mapped IO,配置空间和BAR空间会映射到Host的内存地址空间,区别与DRAM地址,有BIOS来进行地址分配
配置空间/BAR空间:配置空间和Base Adddress Register都属于设备空间,可以映射到主机内存地址空间,访问对应内存地址时就会生成对应的PCIe请求。
传输请求:
①红色箭头表示Memory write流程,CPU修改BAR空间时,会生成对应的PCIe请求,请求路由到PCIe设备上之后由PCIe设备更新
②粉色箭头表示Memory read流程,PCIe设备想要读取内存数据,会先发送一个read请求,RC接收到请求后会从内存中获取对应数据,然后通过CPlD(Completion with data)带回数据,整个过程不需要CPU参与,也就是我们常说的DMA功能。
NVMe概述
PCIe完成了事务层、链路层、物理层的逻辑,那么NVMe就相当于应用层的协议,利用PCIe的高带宽来传输数据。
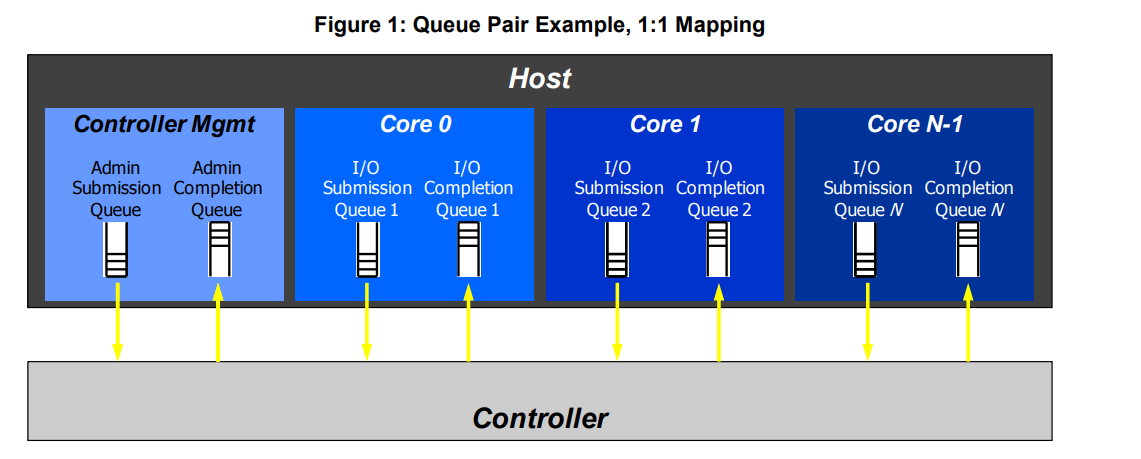
队列是PCIe设备中最常见的概念,host软件和PCIe设备交互基本通过队列来实现,NVMe也是如此。Admin Command 用来创删IO队列等控制命令,IO Command 来负责数据读写等命令。
在PCIe概述中提到了BAR(Base Address Register)空间,NVMe的BAR空间具体信息如下:
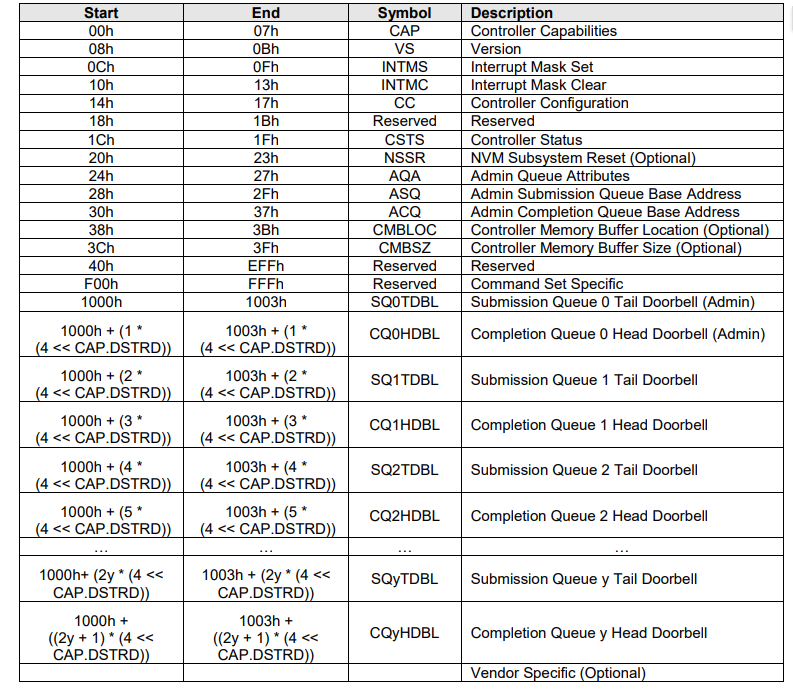
这里面有Admin 队列,SQ Doorbell、CQ Doorbell等信息,而IO队列则是通过下发命令给Admin队列来创建的。
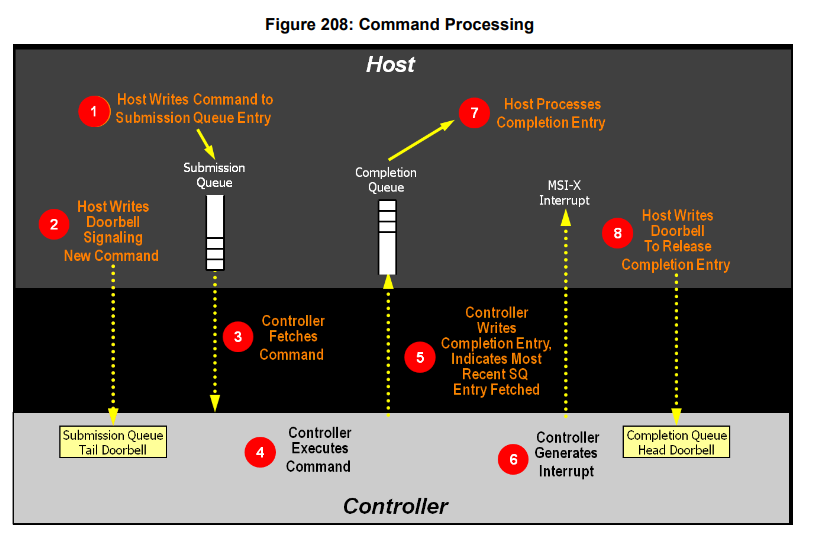
SQ/CQ位于主机内存中,Doorbell是属于NVMe设备的寄存区。结合PCIe的规范来看,具体流程如下:
- Host更新SQ(SQ里有数据的物理地址,通过SGL/PRP来描述)
- 更新BAR空间的Doorbell,RC会生成一个memory write TLP来更新。
- Controller通过memory read 请求来获取到命令和数据
- Controller执行相关读写请求。
- Controller 通过memory write 请求来更新主机内存。
- Controller生成中断来提醒主机(主机也可以通过轮询来避免中断)
- 主机去访问CQ队列,确认命令已经执行完成
- 主机告诉Doorbell CQ队列有成员被消费。
以上便是NVMe与PCIe配合之后,软硬件的大致交互流程, 除了NVMe SSD,网卡、RDMA也基本上都是通过类似的交互方式来完成数据传输的。
内存(pin、DDIO、bar-UIO)
从上述流程中可以看到,NVMe SSD的软硬件交互逻辑主要涉及到两种内存:SSD内部的寄存器(BAR空间);队列以及数据存放的内存。用户态驱动想要利用这两种内存来完成交互还需要解决以下问题:
①用户态驱动不能直接访问BAR空间的物理地址,需要建立相关映射之后通过虚拟地址访问物理地址。
②设备是直接访问的物理地址,需要用户态驱动知道虚拟地址和物理地址映射关系,同时对物理地址连续性要求较高。
③OS一般用页表来管理内存,在内存不够时会换入换出,导致虚拟地址和物理地址映射关系变更,如果初始化之后还有变更会导致设备和驱动软件的内存视图不再一致。需要Pin住页表
④CPU有自己的Cache,而物理设备是直接访问的主存,这也会导致两者之间的内存视图不一致,需要保证DMA内存和Cache的一致性。
让我们来看看这几种内存问题是怎么解决的:
第一个问题(BAR空间映射):
可以通过UIO设备文件或者sysfs文件的mmap,将BAR的物理地址映射到虚拟空间地址中去,这样用户态驱动访问虚拟地址时,就会访问物理地址,RC检测到地址时BAR空间则会成对应的PCIe请求。
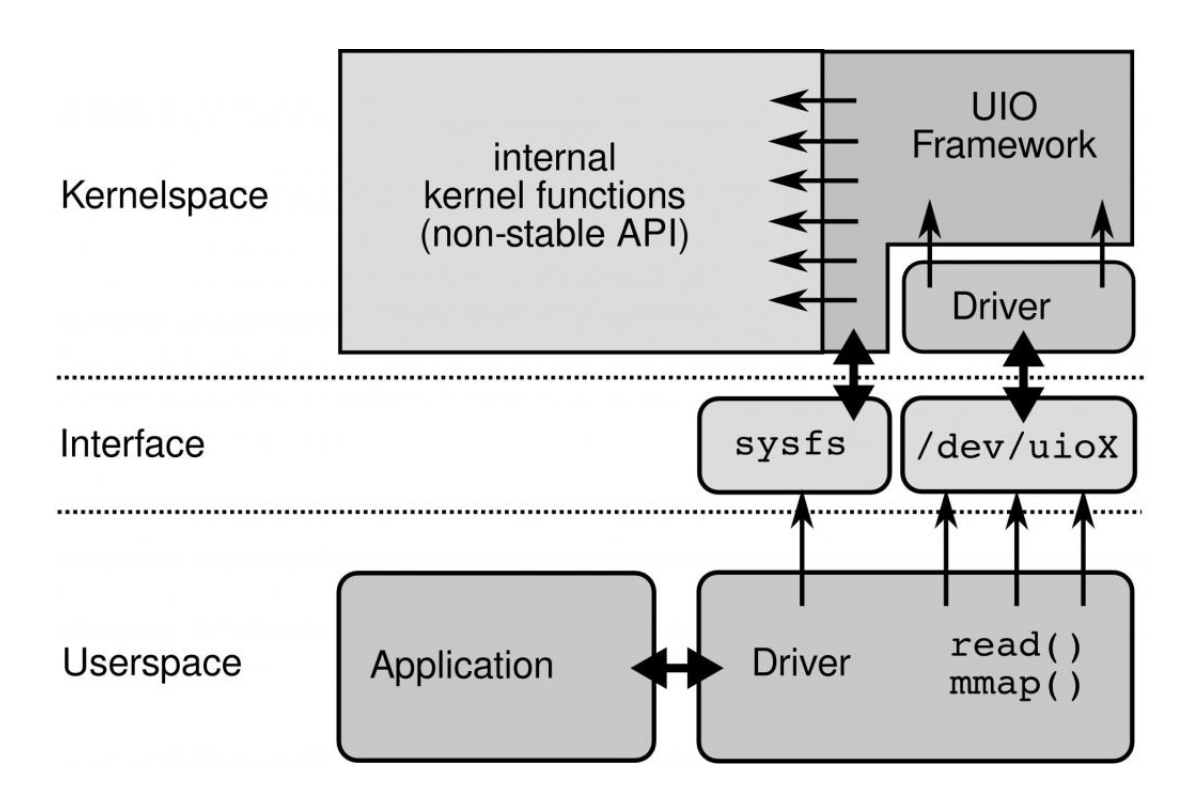
UIO提供了一个驱动框架,实现了mmap功能,可以把相关物理地址映射到进程虚拟地址空间。可以参考UIO使用范例,了解这一功能。
第二个问题(虚拟地址到物理地址转换):
操作系统提供了虚实映射关系的获取方式,最简单的方式就是通过读取/proc/self/pagemap来获取对应物理地址,SPDK的内存管理模块也会保存映射关系,但这要求映射关系不会变更,需要pin住内存页;而物理地址连续可以通过大页内存来实现,也就是下一个问题所提到的。
第三个问题(内存的换入换出):
SPDK通过大页的方式来组建了一个内存池,不仅仅减少了TLB miss的概率,同时大页内存在OS管理时不会被换出到磁盘,这也就保证了映射关系不会变更。
第四个问题(dma 和Cache一致性问题):
第四个问题是最关键的一个问题,也是比较复杂的一个问题。对于PCIe设备来说,通常访问的是主存,而CPU则访问的是自己的Cache,两者之间存在内存视图差异。
如果要保证两者之间的一致性,通常有以下三种做法:
①Disable caching
使用不带cache功能的内存,例如内核的dma_alloc_coherent接口,但是这对性能影响非常大。
②Software managed coherency
通过驱动软件频繁得去Flush Cache和Invalid Cache。以网卡驱动举例,当需要发送数据时,通过flush cache把数据刷到主存,网卡就可以从主存获取到最新数据;当需要接受数据时,通过Invalid Cache使得cache失效,这样驱动软件访问时就可以重新从主存加载新数据。这种方式带来了软件的复杂性,同时限制了性能发挥,并且用户态没有对应权限和接口去Flush/Invalid Cache
③Hardware managed coherency
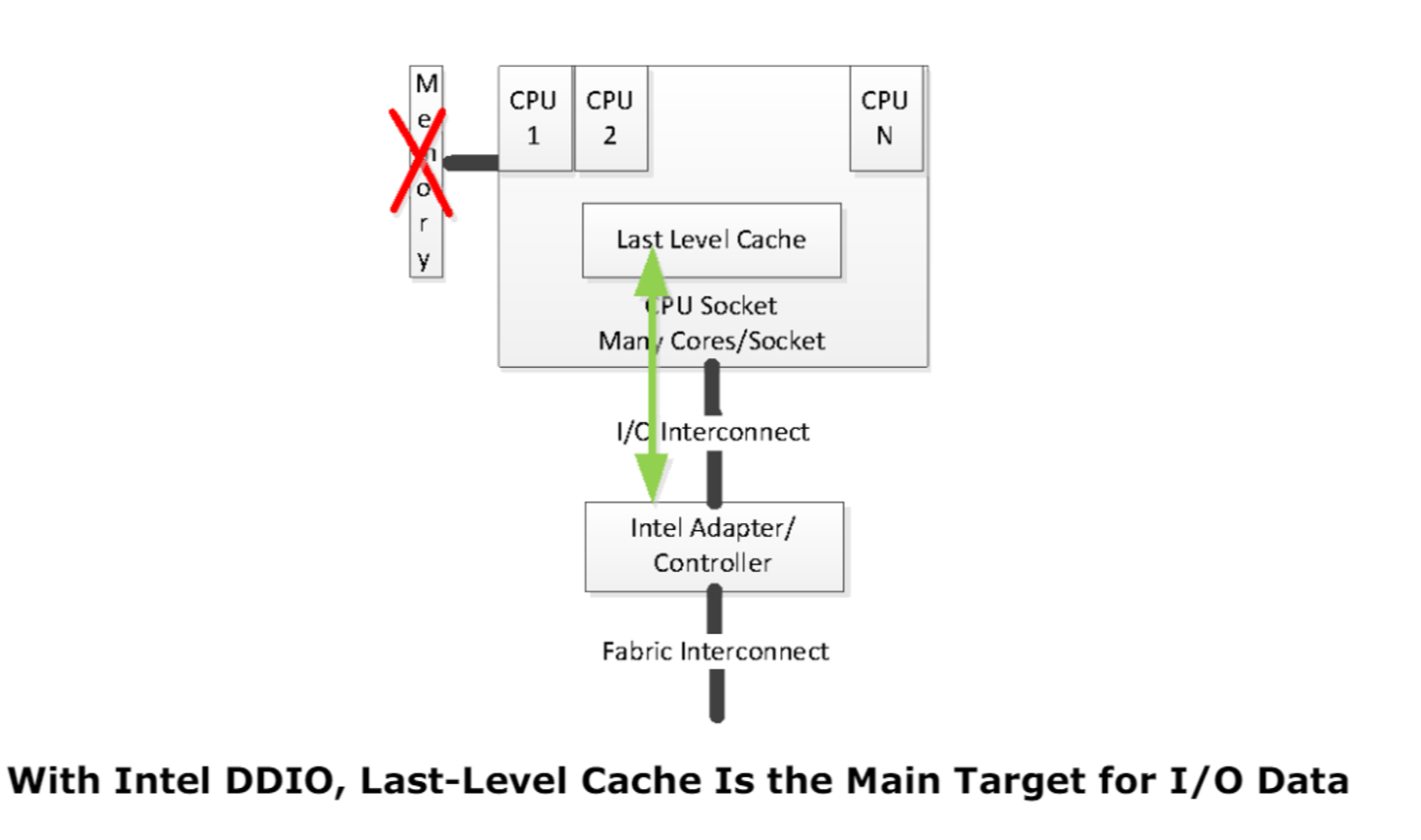
以Intel的DDIO技术为例,PCIe设备可以直接通过CPU cache来访问数据,而无需通过主存来访问。这样通过硬件即可保证了PCIe设备和CPU的内存试图一致,无需软件来额外操作,这也是驱动用户态化的前提。Arm也具备类似的技术,名称为Cache stashing。
dma-cohernt
_CCA
扩展(CXL)
借此机会简单讲下CXL设备的设计理念,CXL的诞生也是为了打破PCIe一些限制。
从上述描述中我们可以发现PCIe与Host软件的交互基本上是用的Host内存,PCIe主要负责搬运数据,而CPU只需要在自己内存中准备好数据,敲一下DoorBell就行了。
如果利用PCIe设备内存,由CPU主动去PCIe内存空间存放数据可不可以?
答案也许是可以的,但是CPU访问PCIe设备内存时需要多次经过事务层和链路层协议,这种访问效率远不如访问自身内存效率高,所以PCIe设计是以PCIe设备为主体,主要由设备来访问主机内存。
而CXL打破了这一限制,我们以CXL SSD为例:
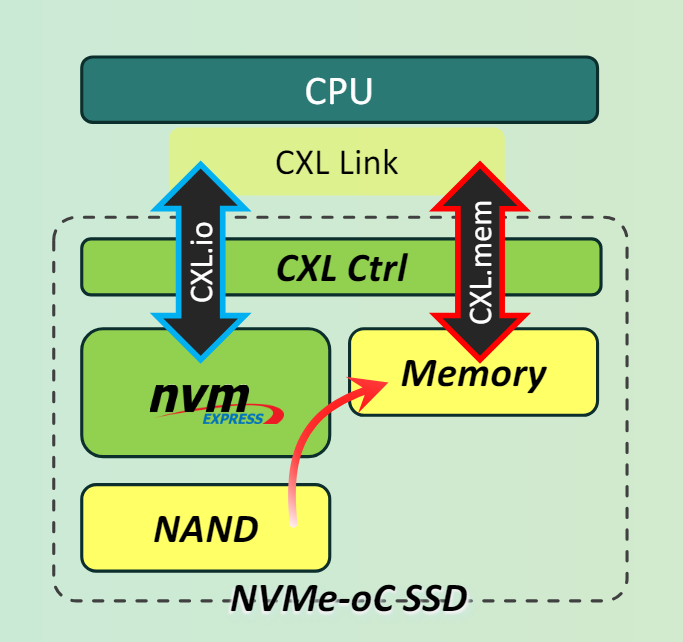
NVMe-oC SSD使用了PCIe的物理层,抛弃了PCIe设备的事务层和链路层。通过CXL.mem协议,Host访问SSD内部内存的时延与Host访问自身的DRAM的时延相当,这样SSD对HOST来说既是个存储设备页相当于一个内存设备了。
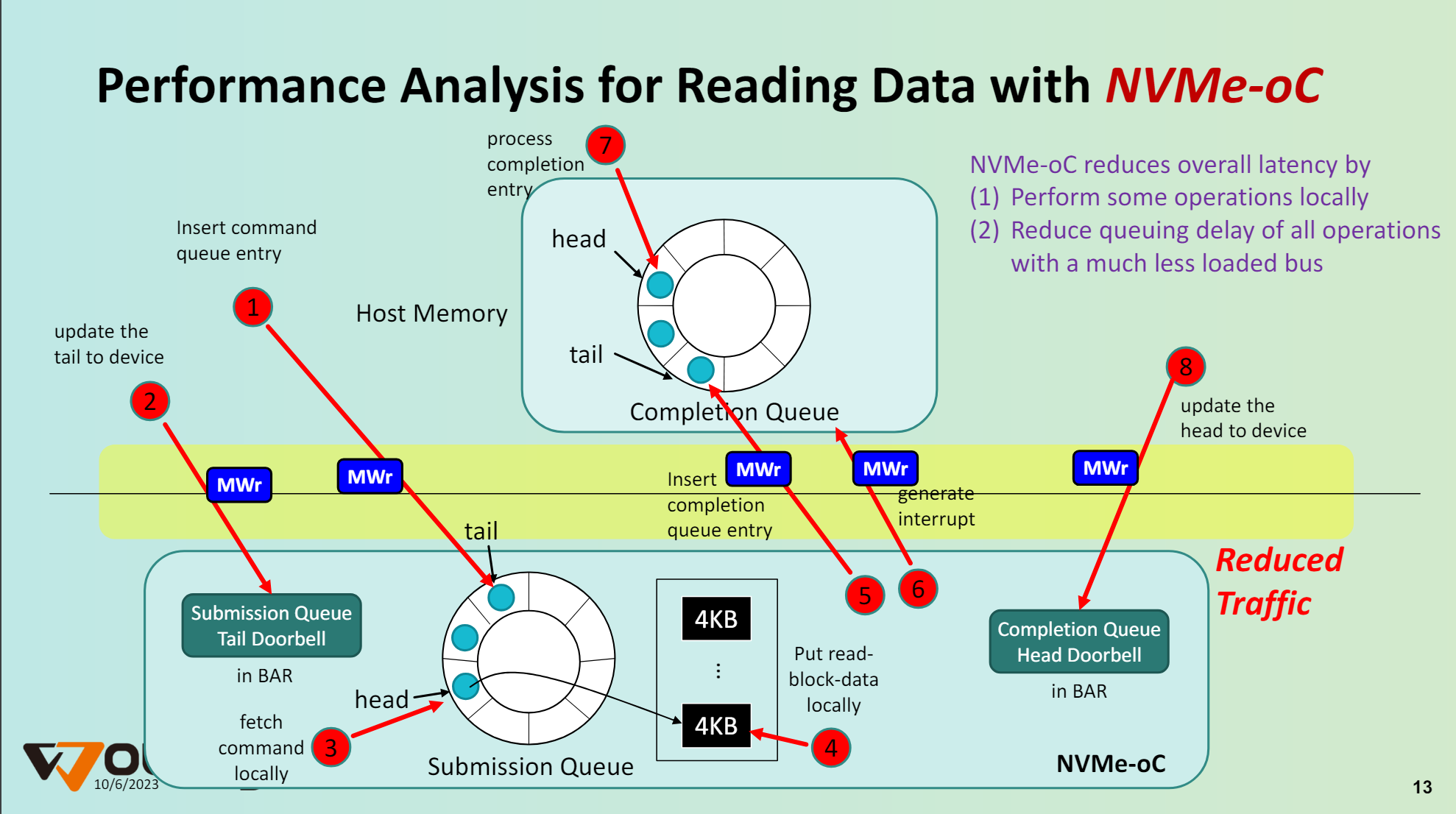
如图是NVMe over CXL的数据流程,与NVMe over PCIe最大的区别则是SQ和数据内存放到了设备一侧,对SSD来说数据放在自身的缓存中即可,不再需要搬运到Host内存中去。CPU访问设备内存也没有什么性能损耗,降低了总线的复杂。