SPDK简介
spdk基本信息介绍

SPDK简介
基本概念
SPDK(The Storage Performance Development Kit )是intel开发的,针对NVMe SSD的一种高性能组件。它主要提供了用户态存储的功能,绕过了kernel,实现了高性能以及可扩展的特性。
SPDK与kernel流程对比
传统的盘读写流程如下:
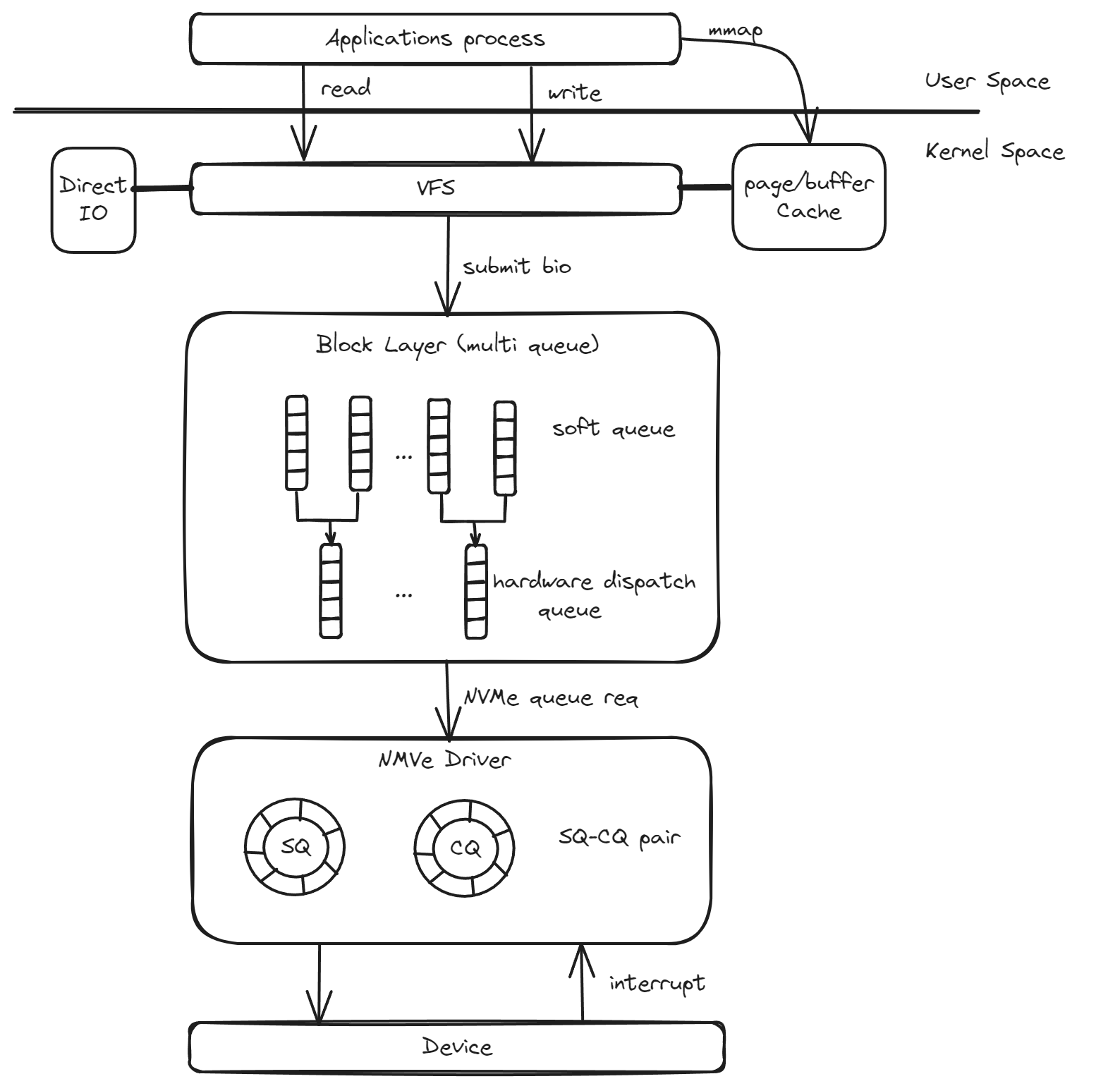
基于内核的读写流程存在以下问题:
- 跨态切换:通过系统调用完成读写功能,会导致频繁的用户态内核态切换,同时在跨态过程中会有数据拷贝。
- 中断:中断导致频繁得上下文切换,影响系统整体性能。
- 内核限制:内核需要处理不同的IO请求,对内核线程的使用不具备灵活性,无法做到线程与硬件队列的1:1绑定,这会导致锁的频繁使用。
- 其他:内核态升级难度高、故障影响范围广等等。
SPDK的编程模型如下:
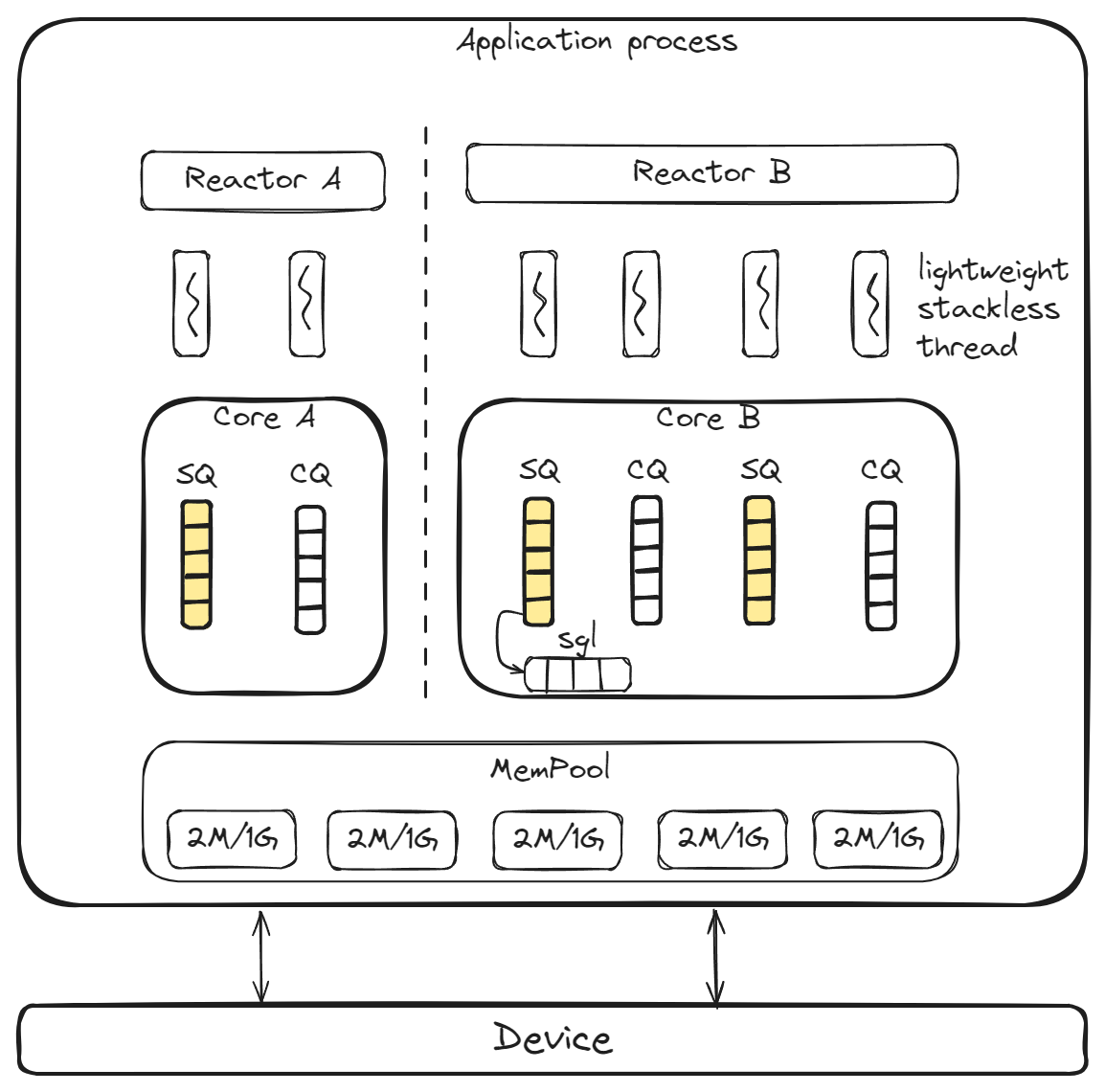
SPDK在用户态提供了通用的内存、线程、队列资源管理以及配合上各个厂商的读写驱动,最大程度得释放了NVMe SSD的读写性能。同时满足可扩展性,当SSD数量、CPU核心数增加时,读写性能也能同步增加。
基于SPDK的读写流程主要有以下特点:
- 用户态驱动:整个IO流程完全在用户态完成,避免了系统调用和拷贝。
- 轮询模式:用户态通过轮询的方式来查询CQ队列中的IO完成情况,避免了中断对系统的影响
- 无锁队列:通过线程、轻量级线程、队列资源的配合做到IO path的无锁化,以及性能的可扩展性。
- 内存管理:大页内存、自定义内存分配,提升TLB命中率以及内存管理效率。
- 其他:Cache Line对齐,NEON/SVE指令
性能报告
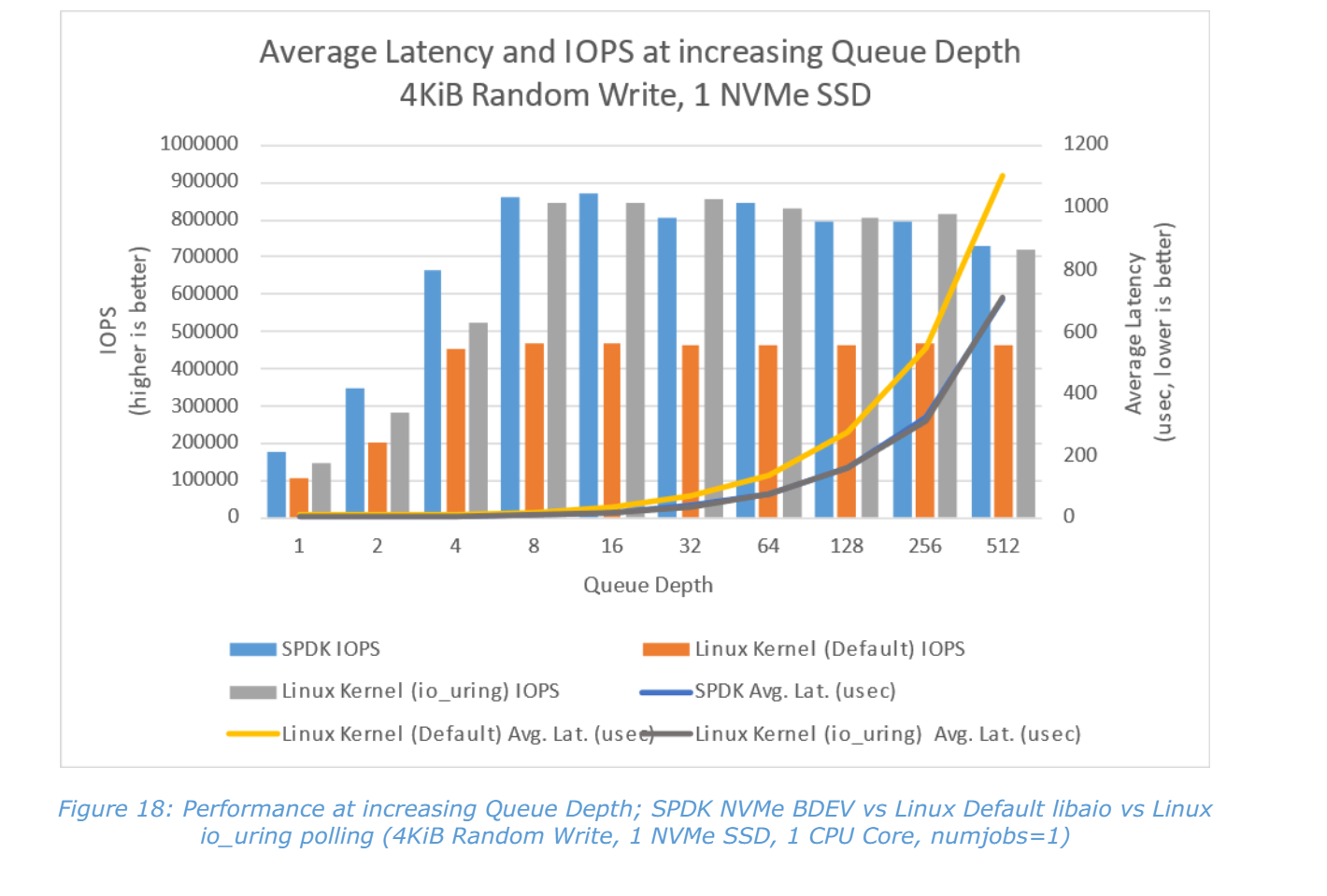
下图是在1 core时,基于不同SSD的数量,整体对外提供的读写性能,可以看出SPDK的性能可扩展性远远好于Linux Kernel。

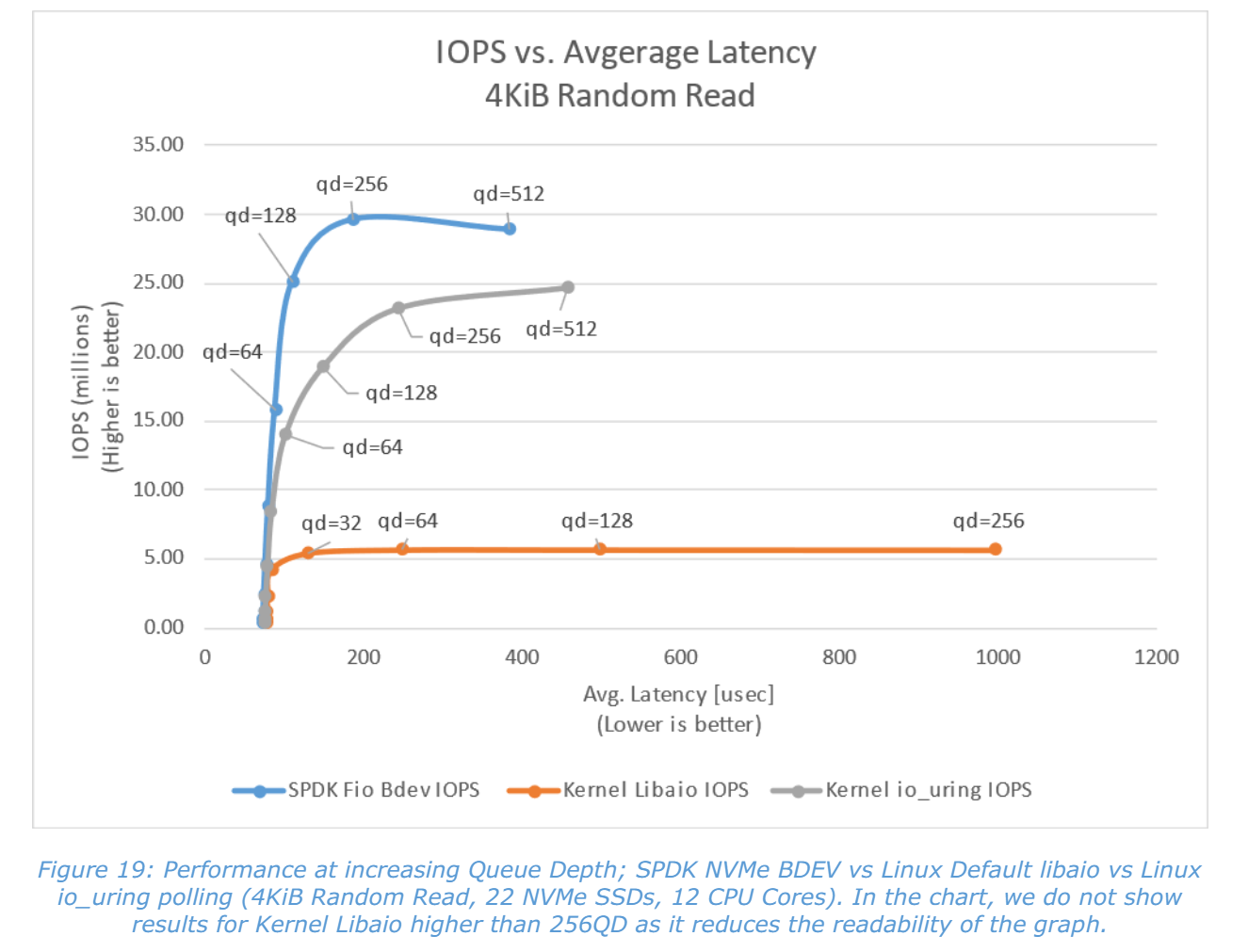
下面两张图,在不同的硬件条件和队列深度下测试,SPDK在时延和IOPS上都有良好表现(其他性能数据可以查看官网)
应用场景:
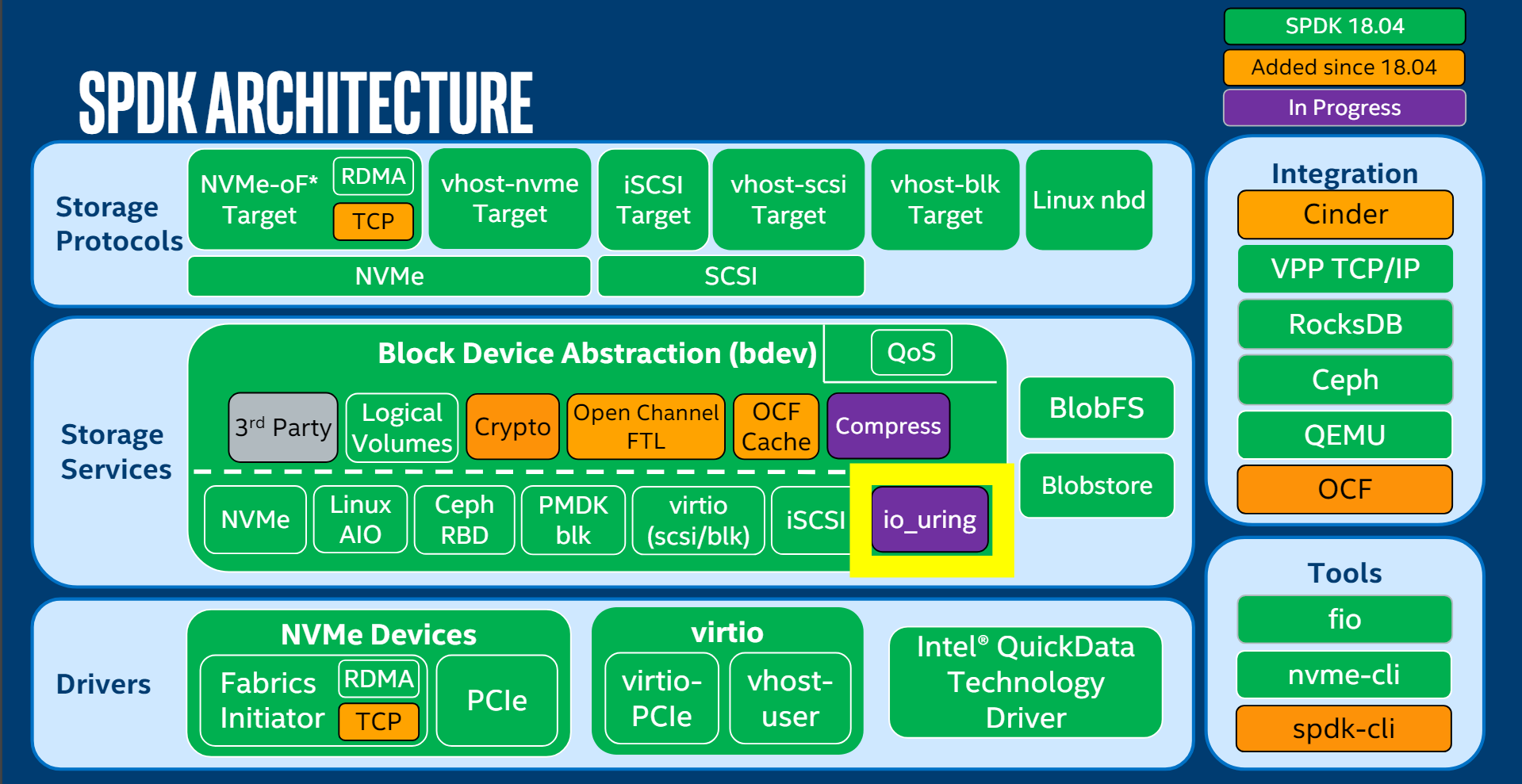
SPDK在驱动基础上还具备了中间服务层,以及网络协议层,可以通过SPDK提供了一个小而全的远端存储服务;同时一些开源存储产品中也在集成SPDK。
总结:
在云存储/分布式/集中式存储、论文、开源项目、异构场景(DPU)、虚拟化场景上都能看到SPDK的身影。
SPDK以及其中的理念已成为存储基础设施中的重要一环,而SPDK中的最重要一环则是用户态驱动。利用硬件和OS的机制将驱动用户态化,同时配合上一些高性能编程思想,就是SPDK具备高性能、可扩展特性的原因。
下文将主要从PCIe和NVMe协议角度来阐述用户态驱动实现的底层原理。
引用:
[1] https://spdk.io/
[2]
This post is licensed under CC BY 4.0 by the author.